
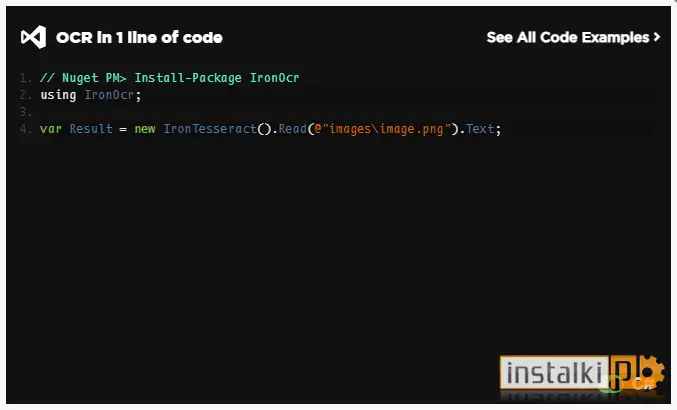
IronOCR to przydatna biblioteka .NET wprowadzająca funkcję OCR, czyli optycznego rozpoznawania znaków z plików PDF i obrazów.
Narzędzie bazuje na zaawansowanym silniku Tesseract, który jest szeroko wykorzystywany na całym świecie.
IronOCR umożliwia skutecznie rozpoznawanie tekstu z dokumentów i obrazów w aż 127 językach. Nie wszystkie są jednak domyślnie zawarte w bibliotece – wystarczy je doinstalować. Wśród obsługiwanych języków znalazł się też polski.
Silnik rozpoznawania może działać w trzech trybach jakości: wysokiej, średniej oraz szybkiej. Deweloperzy mogą dodawać własne języki, a nawet pojedyncze słowa.
IronOCR zawiera w sobie aż trzy wersje silnika rozpoznawania: Tesseract 3, Tesseract 4 oraz Tesseract 5. Możliwe jest jednoczesne wykorzystanie wszystkich wersji w celu poprawy skuteczności rozpoznawania znaków.
IronOCR umożliwia:
- rozpoznawanie tekstu z plików PDF
- rozpoznawanie tekstu z plików obrazu (JPG, PNG, GIF, TIFF, BMP)
- rozpoznawanie tekstu z kodów kreskowych (obsługa ponad 20 rodzajów kodów)
- rozpoznawanie tekstu z kodów QR
- rozpoznawanie tekstu z paragonów, czeków i faktur.
IronOCR jest kompatybilny z następującymi językami .NET: C# VB.NET F#
Uwaga:
Instrukcja instalacji znajduje sie na stronie producenta.

