
Google zaprezentowało nowy model sztucznej inteligencji. Gemini 2.0 potrafi natywnie generować obrazy czy dźwięk, a także wywoływać poszczególne narzędzia. AI ponadto wykona kod oraz uruchomi zewnętrzne funkcje określone przez użytkownika. Koncern informuje przy okazji o niskich opóźnieniach, jak i lepszej wydajności. Dostęp do eksperymentalnej wersji można uzyskać zupełnie bezpłatnie poprzez wybranie stosownej opcji na łamach głównej strony internetowej.
Gemini 2.0 Flash – wersja eksperymentalna
Na początku bieżącego miesiąca byliśmy świadkami wprowadzenia przydatnej nowości do mobilnej odsłony Gemini. Konsumenci są teraz w stanie wykonywać połączenia oraz wysyłać wiadomości tekstowe bez konieczności odblokowywania smartfona. Wystarczy wypowiedzieć stosowną komendę i czekać na reakcję. Teraz przyszedł czas na znacznie pokaźniejszą aktualizację, która powinna odmienić ogólne doświadczenie wielu użytkowników.
Wersja eksperymentalna Gemini 2.0 Flash działa dwukrotnie szybciej od swojego poprzednika. Osiąga też znacznie lepsze wyniki, a przy okazji oferuje szereg nowych funkcjonalności. Mowa przede wszystkim o obsłudze multimodalnych danych wyjściowych: natywnie generowanych obrazach połączonych z tekstem oraz sterowalnego dźwięku TTS w wielu językach. Nie brakuje również opcji wywoływania poszczególnych narzędzi czy zewnętrznych rozwiązać określonych przez konsumenta.
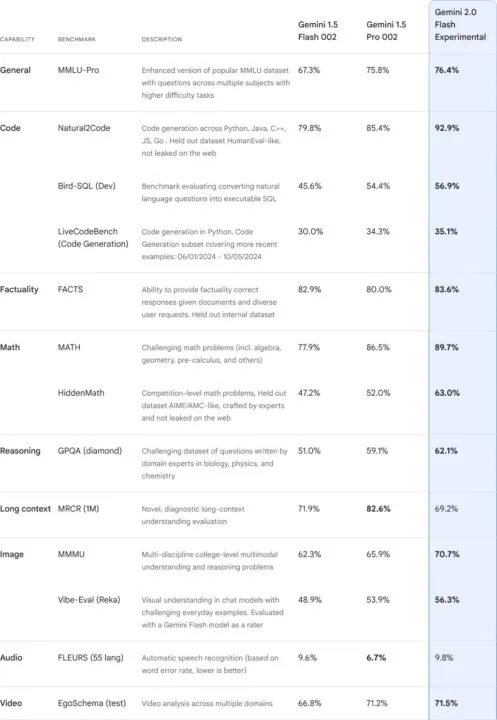
Gemini 2.0 Flash trafił już do aplikacji internetowej na komputerach oraz smartfonach. Użytkownicy na całym świecie mogą korzystać z eksperymentalnej odsłony modelu zoptymalizowanej pod kątem czatu. Google obiecuje, że niedługo nowość pojawi się również w mobilnej aplikacji, natomiast przyszły rok upłynie pod znakiem implementacji ulepszonej AI w innych usługach technologicznego giganta.
Czym są agenci AI?
Usprawnienie sztucznej inteligencji wiąże się również z praktycznym wdrożeniem agentów AI, lecz tak naprawdę w prototypowej wersji. Google nadal jest na wczesnym etapie prac, więc nie należy spodziewać się cudów. Plany mimo wszystko są niezwykle ambitne i obejmują wdrożenie czterech rodzajów agentów – każdy z nich wyćwiczony jest do realizowania całkowicie odmiennych działań.
Project Astra to agenci korzystający z analizy multimodalnej, by rozumieć rzeczywisty świat. Chodzi przede wszystkim o obsługę aplikacji Google, co ma pomóc użytkownikom w wykonywaniu codziennych zadań. Mamy do czynienia z uniwersalnym asystentem, który dzięki Gemini 2.0 jest w stanie m.in. rozmawiać w wielu językach czy skuteczniej zapamiętywać informacje. Nie ma też mowy o długich i nienaturalnych opóźnieniach. Pierwsza grupa zaufanych testerów ma już dostęp do tych rozwiązań, już wkrótce sprawdzą je na prototypie inteligentnych okularów.
Project Mariner to natomiast agenci pomagający w wykonywaniu złożonych zadań. Są oni w stanie zrozumieć oraz przeanalizować informacje znajdujące się na ekranie przeglądarki – tekst, kod, obrazy oraz formularzy. Gdy to się uda, wykorzysta pozyskane dane do wykonania kompleksowych zadań za użytkownika. Na razie całość nie działa jeszcze przesadnie dokładnie i szybko, ale wkrótce ten stan rzeczy powinien ulec zmianie.
Jules określany jest jako „agent kodujący oparty na sztucznej inteligencji”. Jego celem jest integracja z przepływem pracy platformy GitHub. Mowa chociażby o umiejętności rozwiązywania problemów czy opracowywania planów i ich realizacji. Oczywiście nad wszystkim czuwa deweloper, lecz dzięki wsparciu AI wykonywanie obowiązków powinno dostrzegalnie przyspieszyć.
Przygotowano również agentów stosowanych w innych dziedzinach. Pomogą oni w poruszaniu się po grach wideo, a także w robotyce dzięki umiejętności rozumowania przestrzennego. Jak jednak sugerują opublikowane materiały – przeciętni użytkownicy na implementację poszczególnych rozwiązań jeszcze trochę poczekają.
Deep Research dla subskrybentów Gemini Advanced
Deep Research to natomiast „osobisty asystent AI do wyszukiwania informacji”. Wystarczy zadać pytanie sztucznej inteligencji, a ta utworzy plan badawczy składający się z wielu etapów. Gdy go zatwierdzimy, to asystent rozpocznie analizę danych dostępnych na łamach całej sieci. Proces może zająć kilka minut – w tym czasie AI powtórzy proces wiele razy, by finalnie wypluć kompleksowy raport, który możemy eksportować w formie pliku.
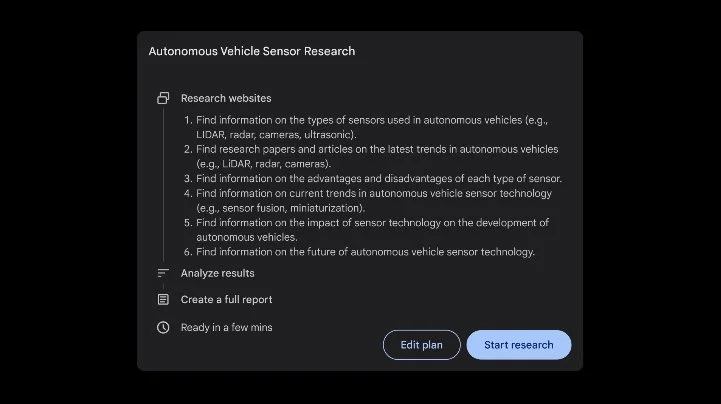
Zostanie on odpowiednio sformatowany i będzie zawierał linki do każdego źródła – nawet tego nieoczywistego. Google chwali się, że jest to świetne narzędzie przede wszystkim dla studentów szykujących się do przedstawienia prezentacji czy przygotowujących skomplikowaną pracę badawczą. Deep Research powinni polubić też założyciele małych firm. AI szybko przeanalizuje sytuację na rynku i przedstawi rekomendacje dotyczące np. odpowiedniej lokalizacji dla siedziby. Użytek zrobią z nowości także marketingowcy.
Obecnie jednak funkcja jest dostępna wyłącznie dla subskrybentów Gemini Advanced i wyłącznie po angielsku. Oczywiście w przyszłości rozwiązanie będzie obsługiwać inne języki, a także pojawi się w mobilnej aplikacji – na razie niezbędne okaże się uruchomienie przeglądarki internetowej.
- Przeczytaj również: Gemini zdziała cuda. Asystent dowie się o Tobie wszystkiego
Trzeba przyznać, że najnowsza aktualizacja robi ogromne wrażenie. Wydano Gemini 2.0 Flash oraz serię prototypów badawczych, co przekłada się na wykonanie sporego kroku przez Google. To oczywiście nie koniec – korporacja zapowiedziała kolejne nowości, lecz ich szczegóły poznamy wkrótce.
Źródło: Google / Zdjęcie otwierające: Google