

Czy myśleliście kiedyś nad tym, żeby zupełnie bezinteresownie przysłużyć się w wolnej chwili do rozwoju jakiegoś ciekawego projektu? Takich w Internecie znaleźć można na pęczki, a po przykłady nie trzeba sięgać daleko. Ot choćby Wikipedia, najpopularniejsza na świecie darmowa encyklopedia internetowa tworzona jest przecież przez tysiące osób z całego świata, które za swój wkład nie pobierają żadnego wynagrodzenia. Podobne projekty można mnożyć. Dziś chciałem podsunąć Wam propozycję współuczestniczenia w ciekawym projekcie Common Voice, za który odpowiada firma Mozilla. Wystarczy, że włożycie minimum wysiłku i poświęcicie chociaż kilka minut dziennie, a pomożecie uczyć maszyny mowy ludzkiej.
Mozilla Common Voice, czyli otwarty system rozpoznawania głosu
Mozilla Foundation słusznie zauważa, że mowa jest dla nas wszystkich rzeczą naturalną i… ludzką. Dlatego właśnie cel nauczenia maszyn rozpoznawania naszej mowy w różnych językach jest zadaniem niezwykle ambitnym. Do tego celu niezbędna jest potężna baza próbek głosów, które muszą być przy okazji weryfikowane pod względem poprawności.
Firma zwraca uwagę na to, że bazy danych wykorzystywane obecnie przez duże firmy są bazami zamkniętymi i niedostępnymi dla mniejszych graczy, co skutecznie hamuje rozwój technologiczny i winduje ceny wdrażania ciekawych innowacji. Stąd właśnie pomysł stworzenia projektu Common Voice, czyli otwartego systemu rozpoznawania mowy dostępnego do każdego.
Tutaj na scenę wkraczacie Wy
Za pomocą witryny Voice.Mozilla.org można rejestrować próbki głosu w wybranym przez Was języku (najlepiej ojczystym), a także oceniać nadesłane już próbki głosu pochodzące od innych internautów.
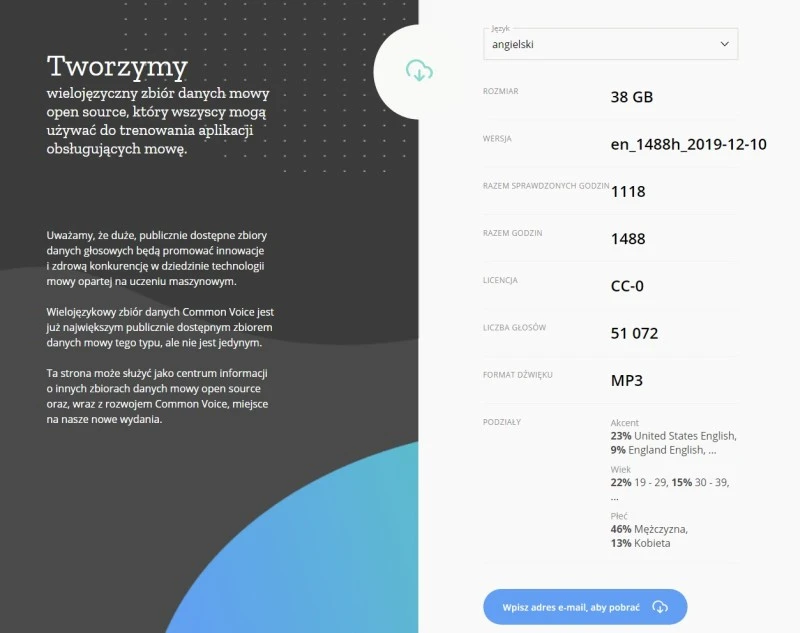
Głosy te współtworzą ogromne bazy danych, które każdy może pobrać po to, aby wykorzystywać je do trenowania aplikacji obsługujących mowę. Dla przykładu, baza danych języka angielskiego zawiera 38 GB danych na licencji CC-0, na które składa się 51 072 głosów i łącznie 1118 sprawdzonych godzin nagrań spośród 1488 nadesłanych. Głosy są męskie i damskie i charakteryzują się różnymi akcentami.
W tej chwili trwają intensywne prace nad stworzeniem stosownej bazy danych głosów z polski, które twórcy aplikacji mogliby następnie pobierać i doskonalić swoje rozwiązania – ta jest obecnie stosunkowo mała. Warto w tym pomóc, poświęcając chociaż 10-15 minut swojego czasu. Nikt nie każe Wam nagrywać próbek – wystarczy oceniać te już istniejące. To także odpowiednia forma wsparcia.
Nie chcecie „pracować” za darmo? Nie bądźcie egoistami
Z rozbawieniem i pewnym przerażaniem śledzę głosy krytyków projektu w sieci, którzy twierdzą, że za darmo nie kiwną w tej sprawie nawet palcem. Te same osoby na co dzień korzystają z darmowych przeglądarek internetowych (w tym Firefoxa) od Mozilli, darmowych aplikacji otwartoźródłowych i czytają wiele darmowych serwisów informacyjnych z włączonymi darmowymi blokerami reklam. Komentarz jest chyba zbyteczny.
Zachęcam Was do oferowania swojego wsparcia. Pokażmy, że polski Internet potrafi zjednoczyć się w słusznej sprawie. Pomóc w rozwijaniu inicjatywy możecie przechodząc pod ten adres.